pandas中set_index( )和reset_index( )以及reindex()区别
在数据分析过程中,对数据表的索引操作是经常会遇到的。尤其在pandas中常用的有几个方法如set_index() 和 reset_index() 以及 reindex() ,这几个方法看着很相近但是如果没有完全搞明白区分它们的不同的话,在日后的使用中会极大影响数据预处理时的工作效率。
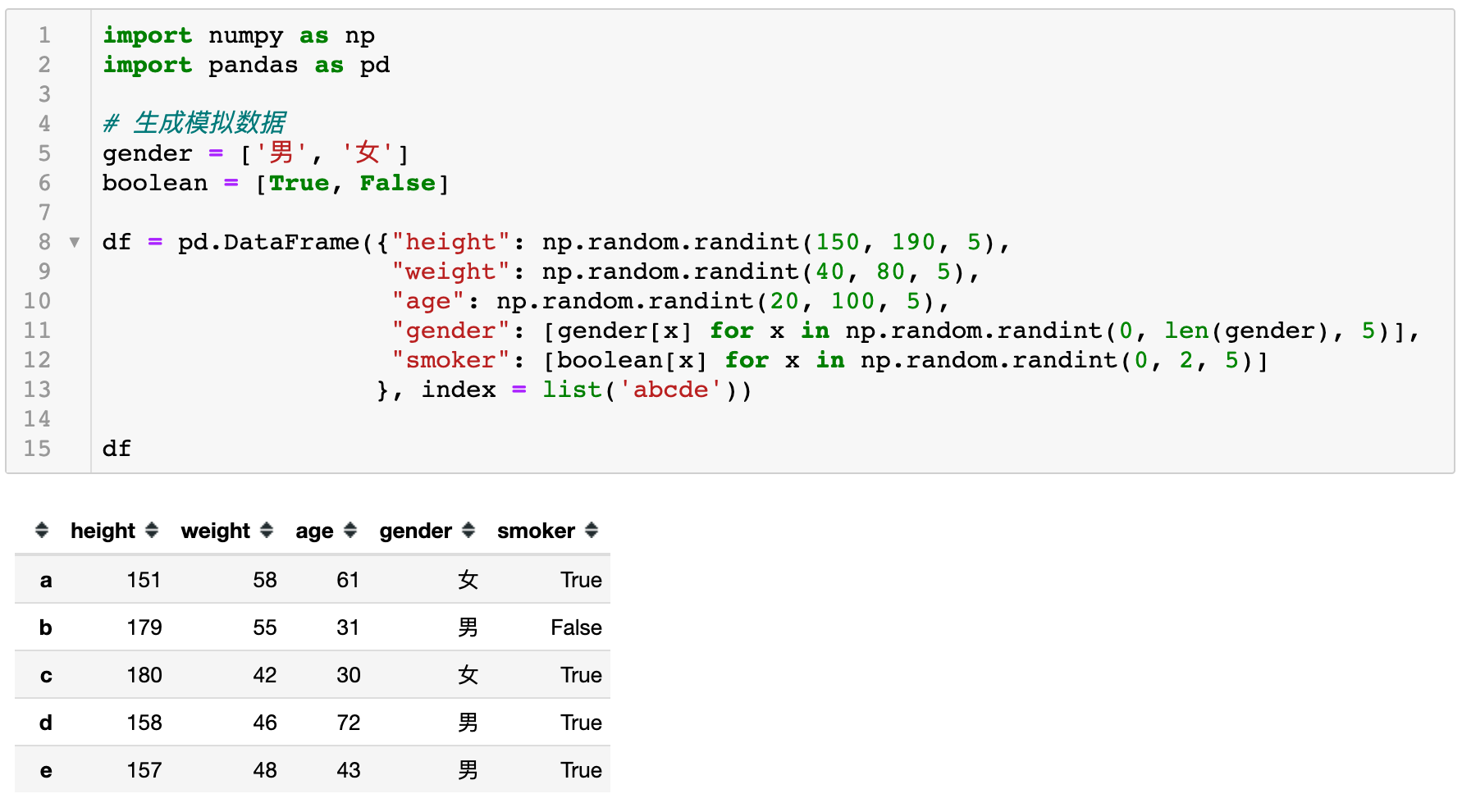
为了更好的以不同例子说明这几个方法的作用与区别,如下先声明一个初始数据集。
一、set_index() 的使用
set_index() 主要可以将数据表中指定的某列设置为索引或复合索引,如下是常涉及使用的几个参数:
- keys:列标签或列标签/数组列表,需要设置为索引的列。
- drop:默认为True,删除用作新索引的列,也就是当把某列设置为索引后,原来的列会移除。
- append:是否将列附加到现有索引,默认为False。
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
如下代码说明,当keys参数设置为height字段时,height字段将变成索引列。同时因为drop=True 代表同时删除原数据中的height列,默认情况本身为True。
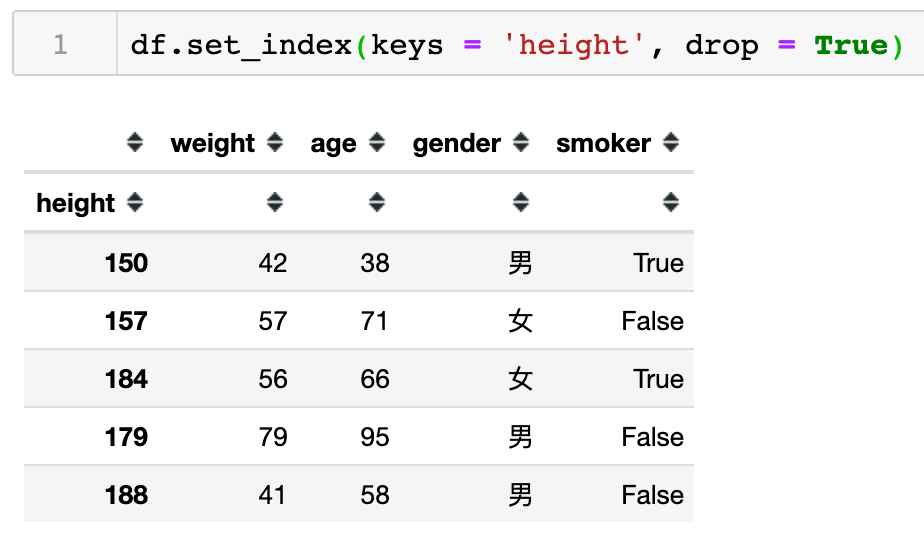
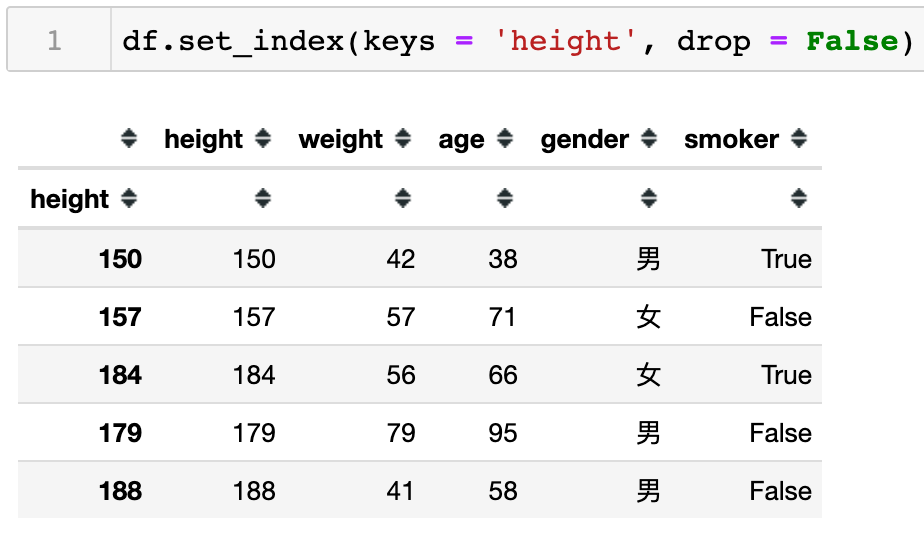
可以发现,当drop=False时,保留了原数据中的height列。
如下代码与之前的代码基本相似,也是将height字段将变成索引列。同时drop=False,代表保留原数据中的该列。但有明显不同之处是设置了append=True,这就代表将height列是以添加的额外附加的形式添加到现有索引中,但并不会把原来最初的索引移除。
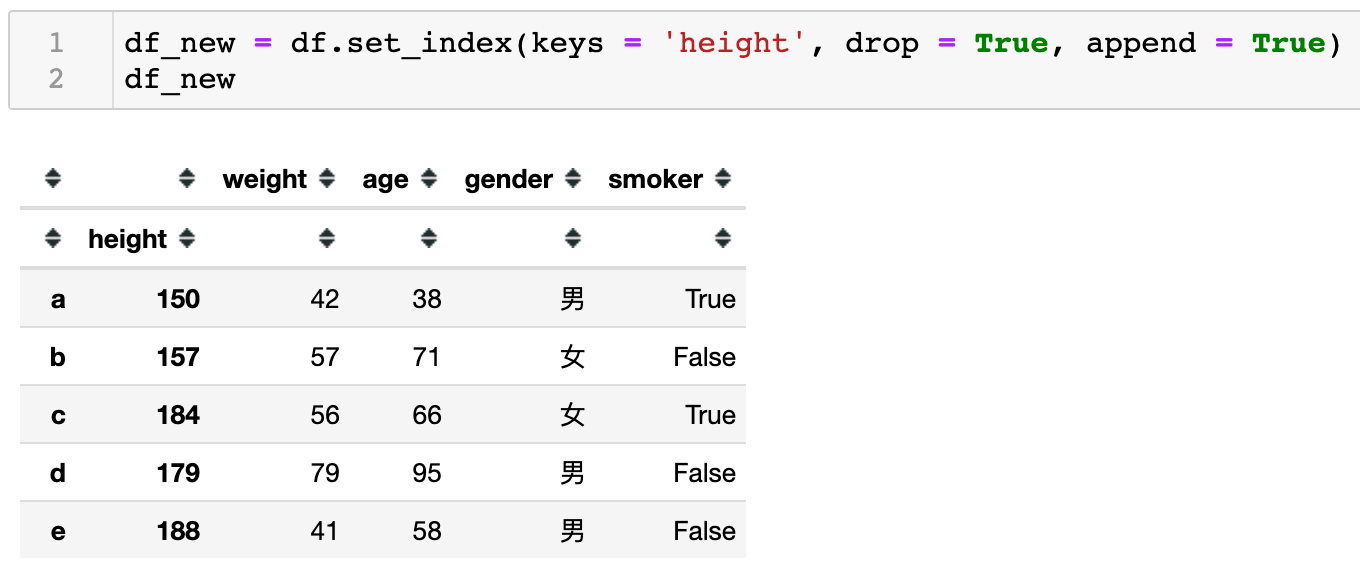
可以看到正因为之前使用了append参数以附加索引的方式添加,如下当查看index索引时会发现得到的索引是复合索引。

二、reset_index() 的使用
reset_index() 主要可以将数据表中的索引还原为普通列并重新变为默认的整型索引。如下是常涉及使用的几个参数:
- level:数值类型可以为:int、str、tuple或list,默认无,仅从索引中删除给定级别。默认情况下移除所有级别。控制了具体要还原的那个等级的索引 。
- drop:当指定drop=False(默认为False)时,则索引列会被还原为普通列;否则,如设置为True,原索引列被会丢弃。
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
如下代码我先通过set_index() 方法将字段age列数据设置为索引,并赋值为新变量df_new,之后会使用reset_index() 方法来说明该方法的作用。
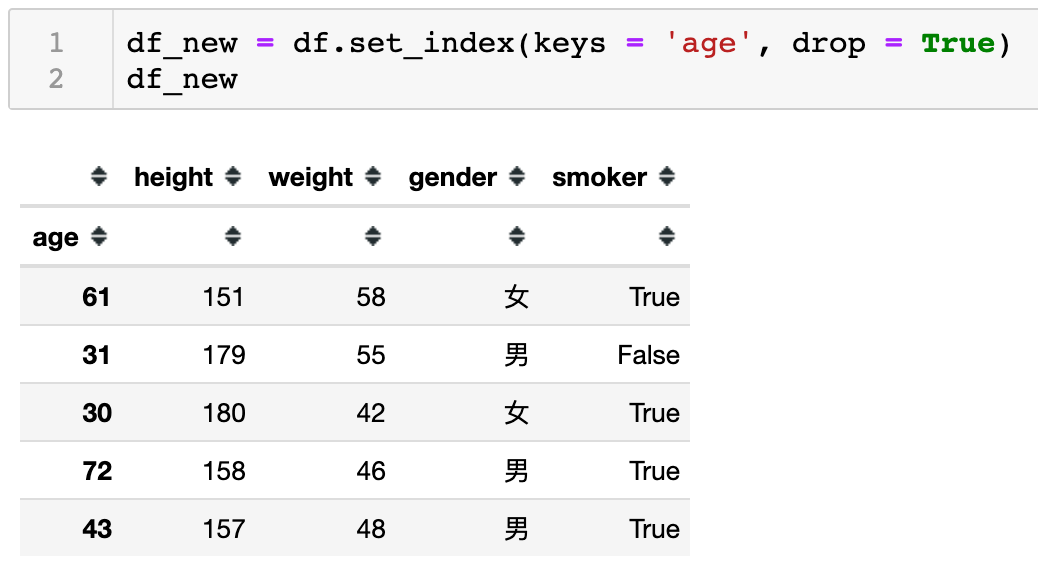
如下,现在针对df_new对象变量使用reset_index()方法,同时设置drop=False(默认为False)代表原来的索引列age会保留并被还原为普通列,同时索引列变为默认的整型索引。
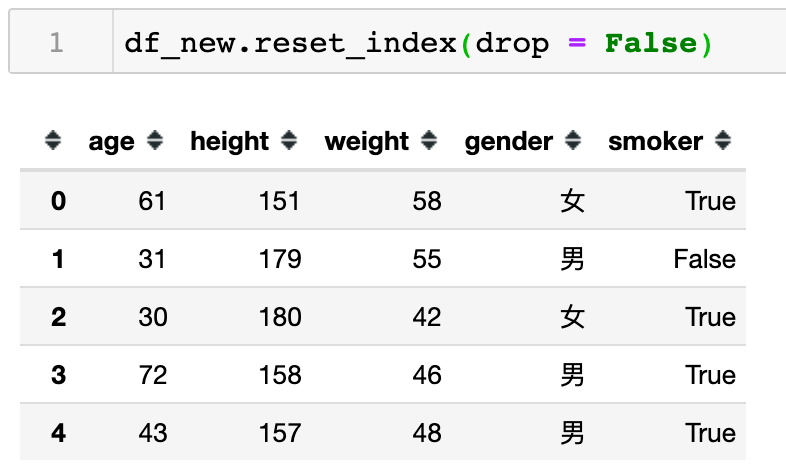
可以发现当drop=True时,除了通过reset_index()重新添加了整型索引后,age索引列已经被移除。

- reset_index() 案例场景说明
理解了方法固然也要明白什么场景下使用,这样才能便于更好的记住。通常在做数据预处理的时候,会对数据表的缺失值或者其它不符合预期的值做移除,这个时候很容易会遇到索引值不在连贯,那么就需要重新设置索引排序。
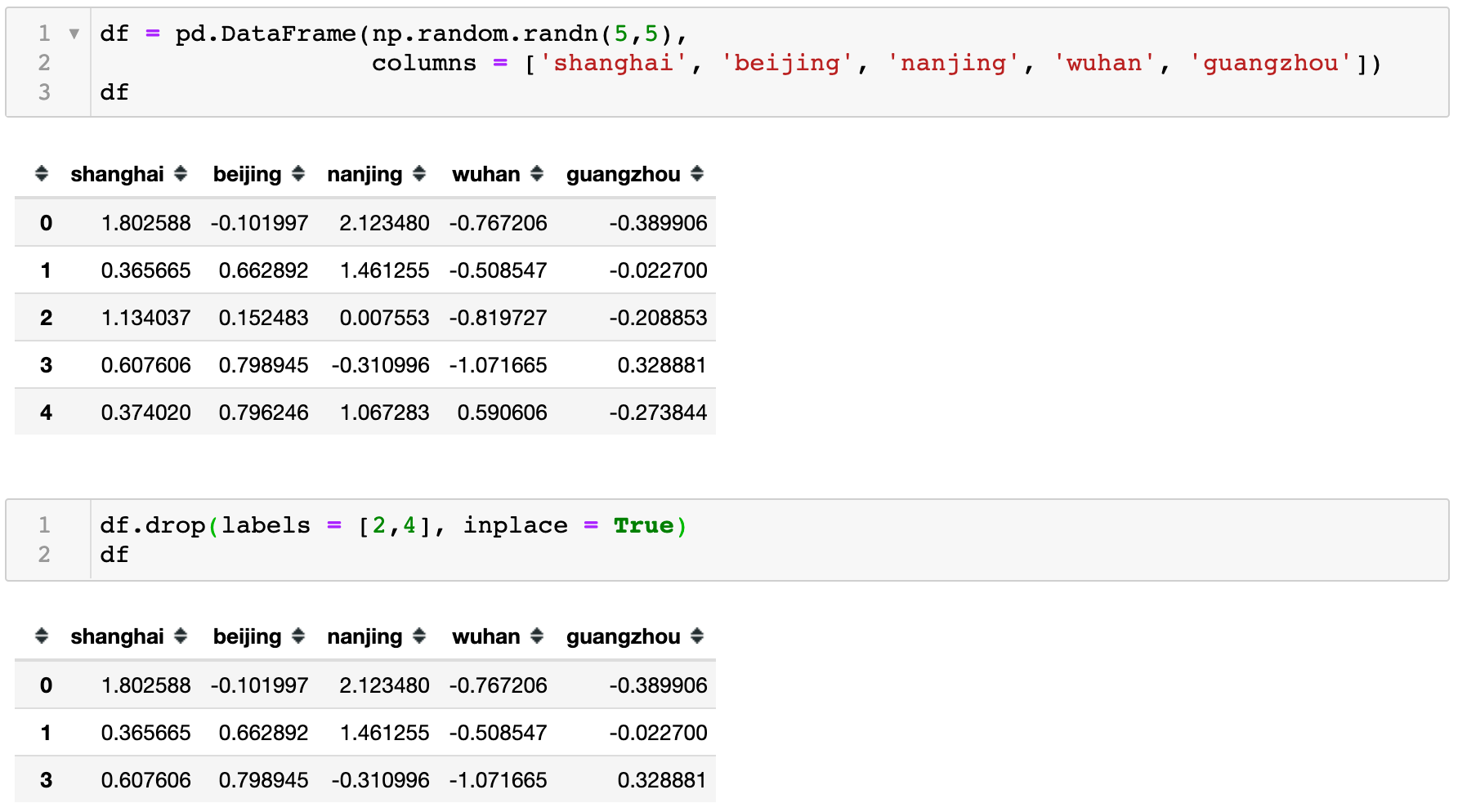
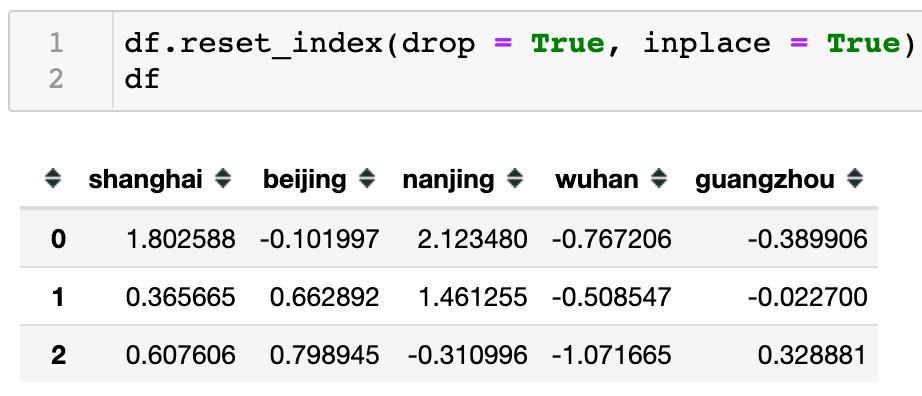
如下例子我先模拟生成了一个5行5列的数据表,它的默认索引为整型索引。因为一些需求通过drop() 方法移除了索引行为2、4的数据。可以从下图看到处理过后的数据只剩下0,1,3索引行数据。
因为经过处理后索引值的排序已经不连贯。为了使整形索引排序连贯,可以回忆下之前的reset_index() 方法可以重新还原整型索引。所以如下代码使用reset_index() 方法很顺利的添加了连贯的整型索引,也正因为默认参数drop=False,所以原来的索引值[0, 1, 3]被还原成了普通列,同时被系统冠名为index字段。

但是通常我们会选择移除该列,所以就像下图那样可以显示设置参数drop = True 进行移除。
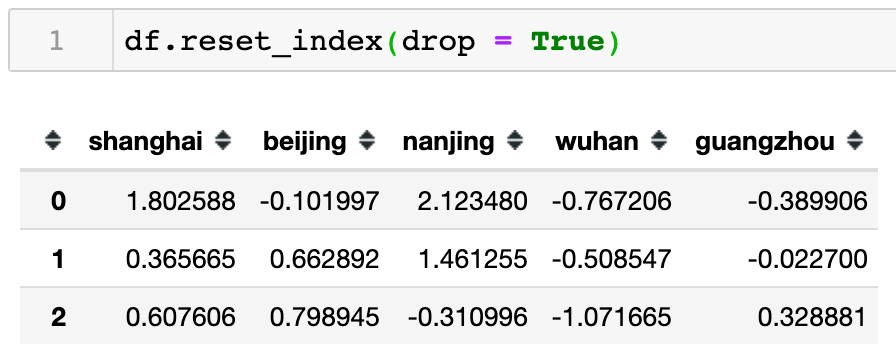
但是千万别忘了,任何移除操作并不会真正修改数据对象本身,如需要一定要设置inplace参数。
三、reindex() 的使用
reindex() 顾名思义它的作用是用来重定义索引的,如果定义的索引没有匹配的数据,默认将已缺失值填充。而索引可以分 “行” 索引与 “列” 索引,所以reindex自然对于两者的修改都可以胜任。它在Series和DataFrame中都非常有用:
对于DataFrame,reindex() 可以修改行、列索引或者两个都修改。
对于Series,reindex() 会创建一个适应新索引的新对象,如果某个索引值当前不存在,就会引入缺失值。
另外,对于以上两个数据类型都可以通过fill_value参数填充默认值,也可以通过method参数设置填充方法。而method包含几个参数可以选择:
- None (默认): 不做任何填充
- pad / ffill: 用上一行的有效数据来填充。
- backfill / bfill: 用下一行的有效数据来填充。
- nearest: 用临近行的有效数据来填充。
Series中的reindex() 使用
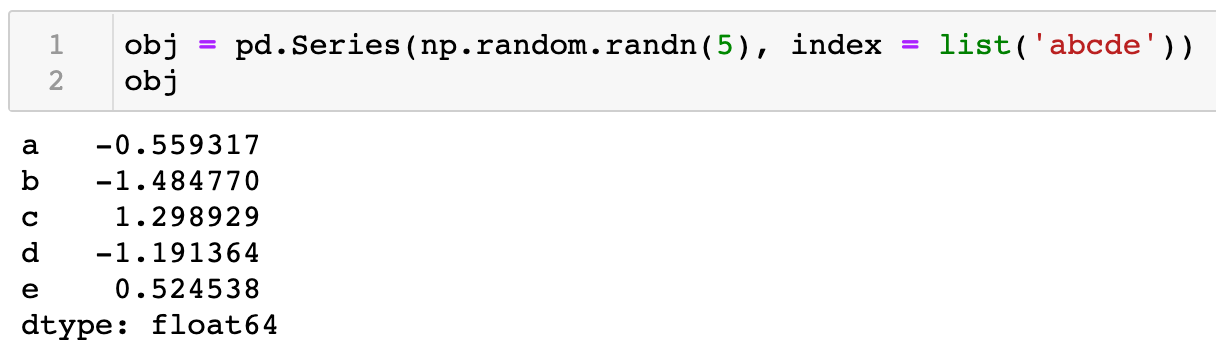
如下例子,先讲解下在Series中reindex() 方法的使用。同样,为了更好的说明,先使用Series初始创建数据,该数据默认的索引为5个字母a, b, c, d, e。
接着,使用reindex() 方法对数据的索引进行重定义为a, b, c, d, e, f。因为f之前并不存在,是我们新定义的,所以也没有匹配的数据值,那么默认就以缺失值NaN填充。当然也可以像下图最后一段代码那样使用 fill_value 参数设定填充数值,这里我设置为0.0。

也可以使用设置method参数来填充,这里使用ffill参数值设定使用上一行的数据来作为填充数据。

DataFrame中的reindex() 使用
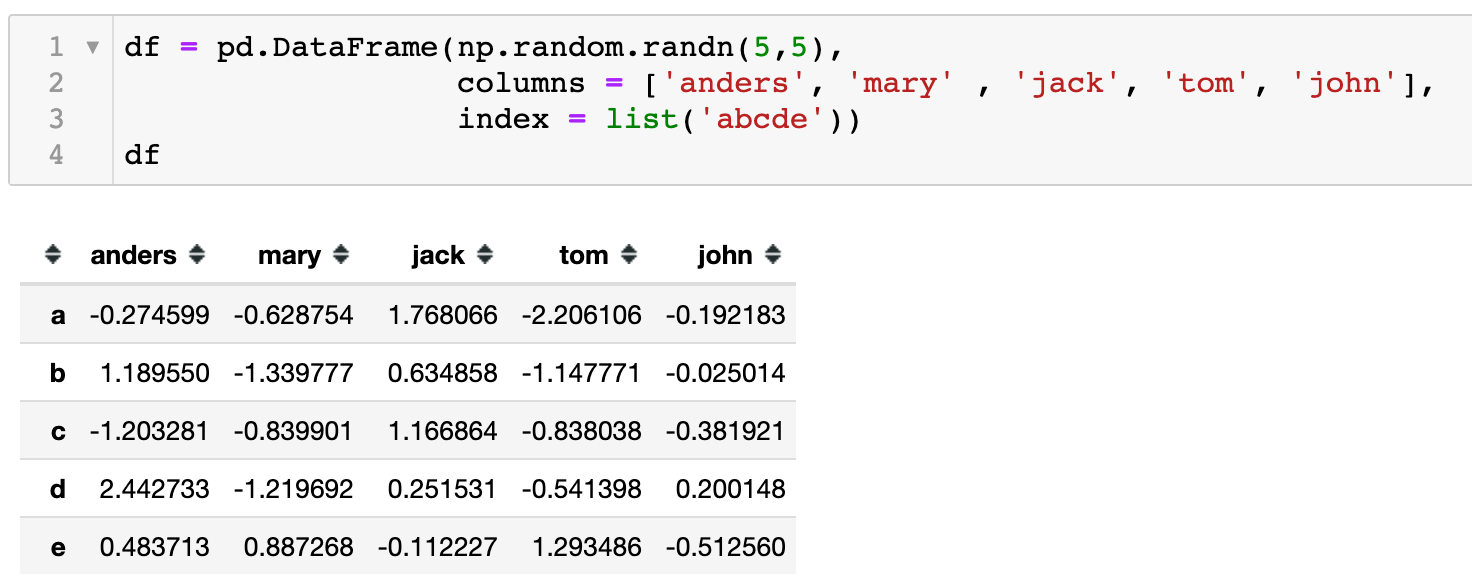
同样,为了更好的说明,先使用DataFrame初始创建数据,该数据默认的索引为5个字母a, b, c, d, e。
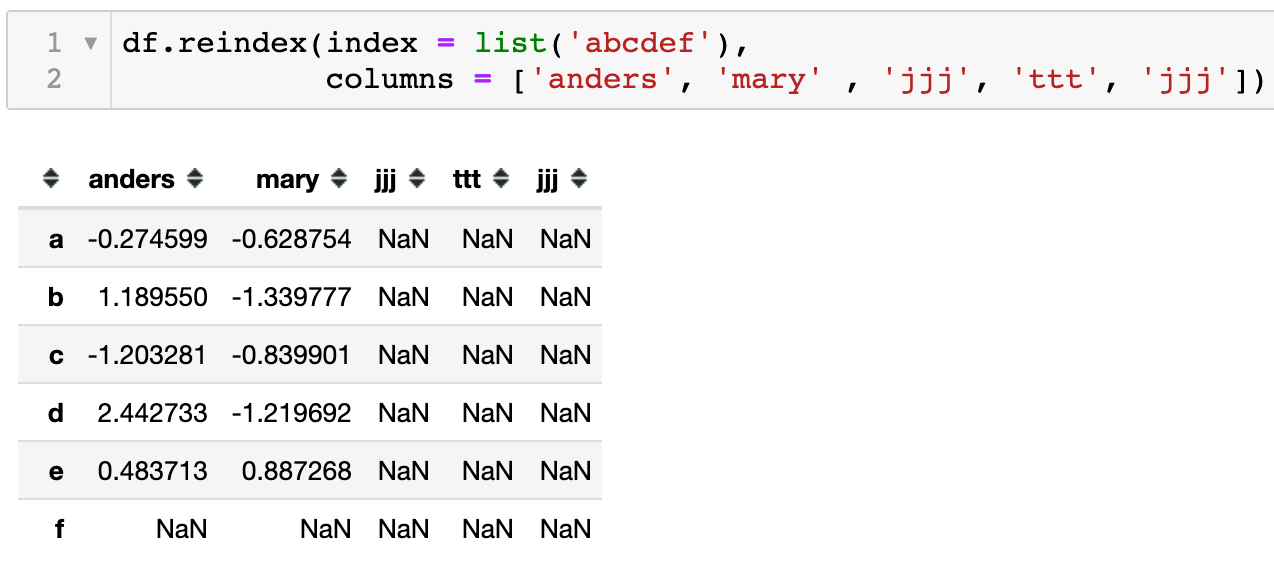
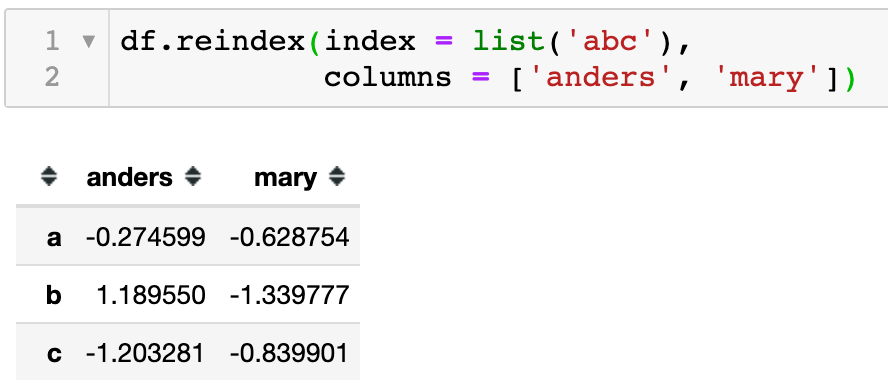
之前提到过在DataFrame中reindex() 可以修改行、列索引。所以如下代码分别对index行索引和columns列索引进行了设置。

当然也可以同时指定index和columns来重定义索引,因为定义的索引既没有匹配的数据也没设置默认填充,所以就以缺失值填充。
当然不仅可以通过重定义索引来增加新索引,反过来也可以做一些移除索引达到drop的效果。
可以看到如在Series中操作reindex() 一样,因为重定义的索引没有找到匹配的对象数据,所以默认填充为缺失值。而在DataFrame中依然可以使用fill_value与method两个参数方法来设定默认填充值。
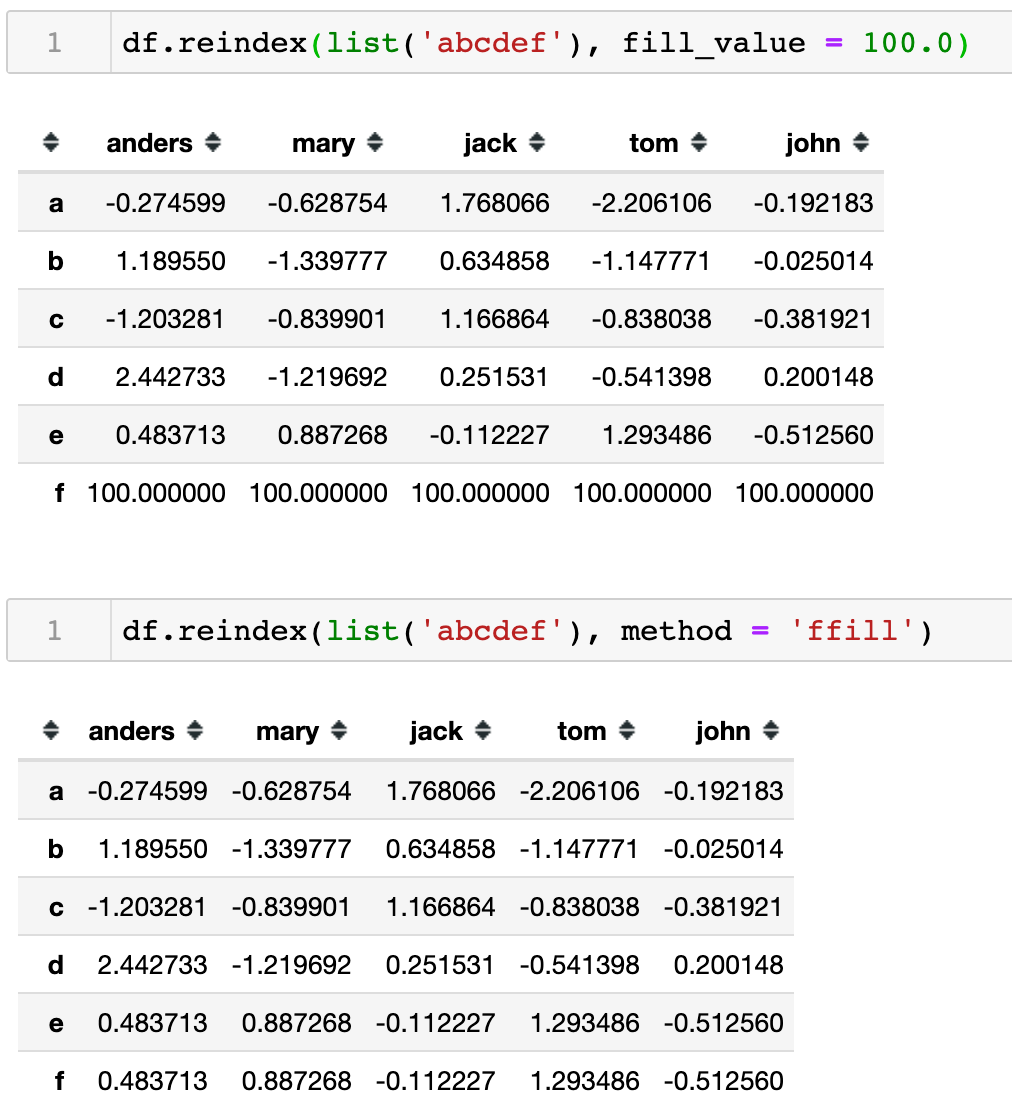
method参数只适用于index是单调递增或者单调递减的情形。同时引用一张网络图很好的说明了method参数的使用逻辑。
